
Как студенты МФТИ создали «Страж» — ML-инструмент для астрономов
В онлайн-магистратуре МФТИ «Науки о данных» студенты могут выполнять дипломную работу на основе реальной научно-технической задачи. Один из таких проектов — «Страж», ML-система для астрономов. Команда собрала MVP, успешно защитила проект, выложила код в open-source и получила пользователей: сейчас «Страж» используют минимум две обсерватории в России.

Зачем ИИ в астрономии
Обсерватории постоянно получают данные о звездном небе: снимки, сведения о яркости объектов, каталоги уже известных звезд. В этих данных могут встречаться переменные звезды — объекты, яркость которых меняется со временем.
Руками такие массивы разбирать долго. Нужно найти объект, проверить его по каталогам, посмотреть, как менялась его яркость, отделить реальную находку от ошибки съемки или оптики. Чем больше данных, тем выше риск пропустить что-то важное.
Эту задачу взяли студенты онлайн-магистратуры Центра «Пуск» МФТИ. Так появился «Страж» — ML-система, которая обрабатывает астрономические данные, ищет объекты на снимках и помогает предварительно классифицировать переменные звезды.
Проект начинался как дипломная работа в формате «Стартап как диплом». Команда работала с реальными астрономическими данными, советовалась с экспертами и в итоге собрала прототип, код которого доступен в open-source.
Что делает «Страж»
«Страж» берет астрономические данные и помогает быстрее найти в них объекты, которые требуют проверки.
Сначала программа ищет звезды на снимке. Затем сверяет найденные объекты с астрономическими каталогами: если объект уже известен, система это видит. Если объекта в каталогах нет, его можно передать на дополнительную проверку.
Еще «Страж» анализирует, как меняется яркость звезды со временем. По этим изменениям программа помогает определить тип переменной звезды: например, затменная, пульсирующая, катаклизмическая или другая.
Для астронома это позволяет сократить объем рутинной работы. Не нужно вручную просматривать каждый фрагмент данных и с нуля проверять объект по каталогам. Машинное обучение помогает быстрее отобрать объекты, которые стоит изучить внимательнее.
Как проект вырос из дипломной работы
«Страж» начался как дипломная работа в формате «Стартап как диплом» в онлайн-магистратуре Центра «Пуск» МФТИ.
В команду вошли трое студентов: Алексей Любезный, Полина Комарова и Якуб Харабет. Они пришли в магистратуру без готовой идеи, но хотели работать с Data Science и реальными задачами.

Научный руководитель проекта Виталий Шелест предложил им тему на стыке машинного обучения и астрономии: автоматизировать поиск небесных объектов. Так команда начала собирать «Страж».
Сначала студенты изучали открытые астрономические каталоги: Gaia, TESS, VSX и другие. Потом собирали первые версии системы, проверяли, как она ищет объекты и классифицирует переменные звезды.
В работе помогали внешние эксперты. Станислав Короткий, старший научный сотрудник и руководитель проекта AstroAlert в обсерватории «Ка-Дар», консультировал команду по астрономическим данным. Михаил Топчило, руководитель роботизированной астрономической обсерватории в Оренбурге и проекта «Смотри на звезды», поддержал студентов и передал им отснятые материалы. Кирилл Соколовский, научный сотрудник кафедры астрономии Иллинойсского университета в США, тоже консультировал команду по проекту.
Позже студенты получили поддержку Yandex Cloud. Сергей Кукуруз и Даниил Ефимов помогали с облачной инфраструктурой и вычислениями. Это позволило хранить большие массивы данных, обучать модели и быстрее проверять гипотезы.
Дипломная работа стала проектом с реальными данными, внешними экспертами, облачной инфраструктурой и проверкой результатов.
Первые прогоны и работа над ошибками
Команда осваивала облачные мощности и обучала модель 2,5 месяца. После этого начались тестовые прогоны — и «Страж» стал выдавать первые результаты.
Один из первых успешных прогонов выявил более 360 объектов, которые можно было принять за новые. Сначала результат выглядел впечатляющим. Но команда поняла: все слишком хорошо, чтобы быть правдой.
Разработчики обратились за консультацией к астрономам. Выяснилось, что часть находок связана с артефактами, особенностями оптики и ошибками в данных. На снимках могут появляться пятна, шумы, искажения или объекты, которые выглядят необычно, но не свидетельствуют об обнаружении нового небесного тела.
После консультаций команда пересобрала часть данных, улучшила датасеты и сократила число аномалий. Затем результаты передали научному сотруднику обсерватории «Ка-Дар» на проверку. Он нашел несколько методологических ошибок и подсказал, что нужно доработать.
После этих правок «Страж» стал точнее работать с реальными наблюдениями. Команда увидела, что в Data Science мало обучить модель — нужно разобраться в данных, проверить выводы с экспертами и несколько раз пройти путь от ошибки к новой версии.
С какими данными и технологиями работала команда
«Страж» работает с двумя типами данных: снимками звездного неба и временными рядами. Временной ряд показывает, как менялась яркость звезды в разные моменты наблюдения. По этим изменениям модель помогает отнести объект к одному из классов переменных звезд: Eclipsing, Eruptive, Pulsating, Rotating, Cataclysmic.
Команда сверяла найденные объекты с каталогами Gaia DR3 и VSX. Если объекта нет в известных каталогах, его можно передать на дополнительную проверку. Если объект уже описан, система помогает быстрее понять, с чем именно работает астроном.
Для обучения модели собрали сбалансированный датасет из 100 000 объектов. Их отобрали из 1,5 млн исходных записей. Такой объем помог снизить нагрузку на вычисления и сделать обучение более управляемым.
Отдельной задачей стала работа с большими массивами данных. Команда работала с 6 ТБ астрономических наблюдений. Для хранения данных взяли Yandex Object Storage, для работы с моделями — Yandex DataSphere.
С высокой нагрузкой столкнулись почти сразу: большие данные занимали много памяти, а обработка шла медленно. Чтобы ускорить работу, разработчики уменьшили выборку для баланса классов и перенесли часть вычислений на GPU через библиотеку cuDF.
За классификацию отвечала нейросетевая модель. В ее архитектуре были сверточные слои Conv1D и PrototypeLayer. Conv1D помогал находить паттерны во временных данных. PrototypeLayer сравнивал данные с эталонными представлениями классов: модель смотрела, на какой класс объект больше похож, и на основе этого делала предварительную классификацию.
Что получилось
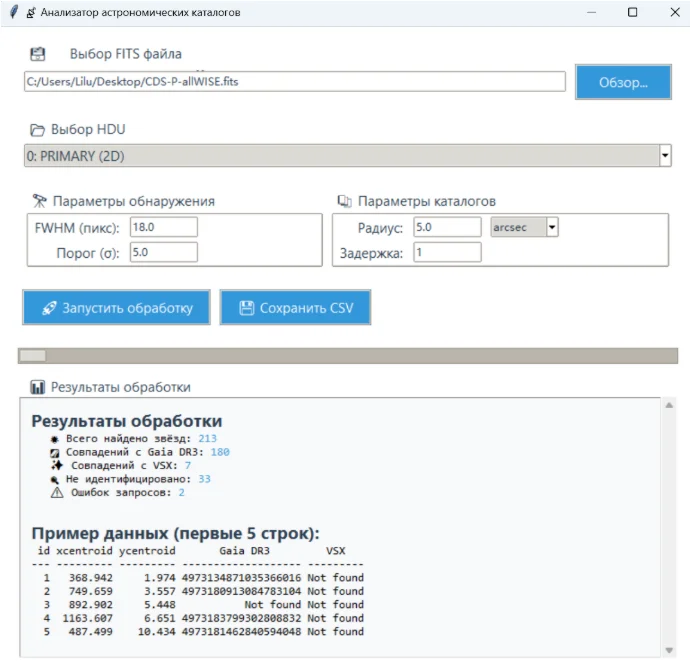
В 2025 году команда собрала MVP «Стража» и успешно защитила проект. Система работала с FITS-файлами, извлекала характеристики светимости звезд и проводила предварительную классификацию.
«Страж» мог анализировать данные обсерваторий с точностью до 98% и работать в 5 раз быстрее ручной обработки.
О проекте вышли публикации в СМИ и большая статья на Хабре. Код по-прежнему доступен в open-source, поэтому астрономы и исследователи могут изучать его, запускать у себя и дорабатывать под свои задачи.
Сейчас «Страж» используют минимум две обсерватории в России. Еще интерес к проекту есть у коллег из обсерватории в Калифорнии, хотя международный диалог идет сложно.
Где работать с такими проектами
«Страж» стоит на стыке Data Science, инженерии и науки. В таких проектах нужно уметь работать с большими данными, обучать ML-модели, разбираться в предметной области и говорить с экспертами на одном языке.
Этому учатся в онлайн-магистратуре «Науки о данных» МФТИ. Программа длится 2 года и проходит онлайн. Внутри есть 3 профильных трека: Machine Learning, Data Engineering и Data Analysis.
Студенты изучают машинное обучение, глубокое обучение, системы хранения и обработки данных, развертывание ML-моделей, компьютерное зрение, NLP, рекомендательные системы и инструменты Big Data.
Отдельная часть обучения — практическая работа. Студенты решают учебно-практические задачи, работают с бизнес-кейсами в формате хакатонов и кейс-чемпионатов, а выпускную квалификационную работу могут выполнить в одном из трех форматов: стартап, корпоративный проект или исследование.
«Страж» показывает, как может выглядеть такой диплом: студенты взяли данные обсерваторий и собрали ML-систему, которой уже пользуются астрономы.
Если вы хотите работать с машинным обучением и большими данными не только на учебных примерах, обратите внимание на онлайн-магистратуру «Науки о данных» МФТИ.